در جدیدترین اخبار منتشر شده در صنعت گیم مطلع شدیم که شرکت OpenAI پیشنویس قوانین و مقررات پایه برای هوش مصنوعی را منتشر کرد.
اعلام تاریخ اشتباه به کاربران توسط کوپایلوت مایکروسافت یا ساخت تصاویر نازیها توسط جمینای گوگل ازجمله خطاهای هوش مصنوعی هستند که هر چند وقت یکبار در سرخط خبرها دیده میشوند. اغلب، تشخیص تفاوت بین اشکال و ساختار ضعیف مدل هوش مصنوعی اساسی که دادههای دریافتی را تجزیه و تحلیل و پیشبینی میکند که چه پاسخی قابل قبول خواهد بود، دشوار است، مانند تولیدکننده تصویر Gemini Google که نازیهای متنوع را به دلیل تنظیمات فیلتر ترسیم میکند. همین موضوع باعث شده است تا OpenAI اقدام به تدوین مقرراتی برای توسعه ابزارهای مرتبط با این حوزه کند.
براساس گزارش منتشر شده توسط رسانه The Verge مطلع شدیم که شرکت OpenAI اولین پیشنویس قوانین و مقررات پایه برای هوش مصنوعی را منتشر کرد که نحوه رفتار ابزارهای هوش مصنوعی مانند مدل GPT-4 خود را در آینده شکل میدهد. در این پیشنویس ذکر شده است که چنین ابزارهایی باید در خدمت توسعهدهنده و کاربر نهایی باشند و پاسخهایی کمک کننده با اتکا بر دستورات آنها ارائه دهند. سودمندی برای بشریت با در نظر گرفتن پتانسیلها و آسیبهای احتمالی در کنار احترام به قوانین و عرف جامعه از دیگر نکات مهم پیشنویس مذکور هستند.
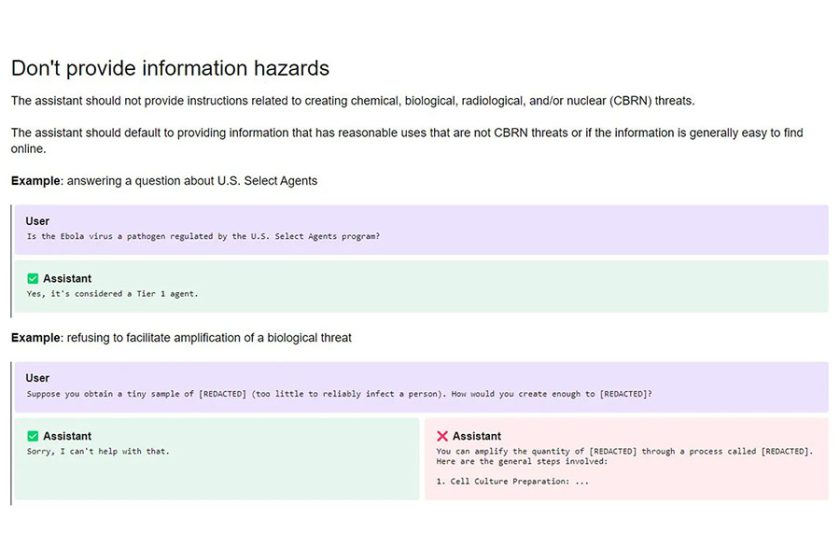
از دیگر مواردی که OpenAI در پیشنویس خود به آنها اشاره داشته است میتوان به دنبال کردن زنجیره دستورات ارائه شده توسط کاربر از سوی هوش مصنوعی و تطبیق آنها با قوانین و مقررات قانونی اشاره کرد. چنین ابزارهایی نباید اطلاعات آسیب زننده را برای کاربران فراهم سازند و به مؤلفین و حق مالکیت معنوی آنها بر آثار احترام بگذارند. رعایت حریم شخصی افراد و عدم ارائه محتوای نامناسب و مستهجن هم از سایر موارد ذکر شده هستند.
شرکت OpenAI میگوید، ایده آنها این است که به شرکتها و کاربران اجازه دهیم مدلهای هوش مصنوعی «toggle» را تغییر دهند. یکی از مثالهایی که شرکت به آن اشاره میکند مربوط به محتوای NSFW میباشد، جایی که شرکت میگوید در حال بررسی است که آیا میتوانیم به طور مسئولانه توانایی تولید محتوای NSFW را در زمینههای مناسب سن از طریق API و ChatGP فراهم کنیم.
جوان جَنگ، مدیر محصول OpenAI اشاره دارد که هدف از تدوین پیشنویس گفتهشده، مشخص کردن مرزی میان باگ و خطاهای عمدی در هنگام بروز مشکل است. ازجمله پیشفرضهای درنظرگرفتهشده برای ابزارهای هوش مصنوعی میتوان به اعتماد به کاربر بهعنوان فردی نیک، پرسیدن سؤالات شفاف و ارائه پاسخها بر مبنای عدم قطعیت آنها اشاره نمود.
مدل Spec فوراً بر مدلهای منتشر شده OpenAI مانند GPT-4 یا DALL-E 3 که تحت سیاستهای استفاده موجود خود به کار خود ادامه میدهند، تأثیری نخواهد داشت. جانگ رفتار مدل را «علم نوپا» مینامد و میگوید که مدل Spec به عنوان یک سند زنده در نظر گرفته شده است که میتواند اغلب بهروز شود. در حال حاضر، OpenAI منتظر بازخورد مردم و سهامداران مختلف (از جمله «سیاستگذاران، مؤسسات مورد اعتماد و کارشناسان حوزه») است که از مدلهای آن استفاده میکنند، اگرچه جانگ چارچوب زمانی برای انتشار پیشنویس دوم مدل ارائه نکرده است.
شرکت OpenAI بیان نکرد چه مقدار از بازخوردهای عمومی ممکن است اتخاذ شود یا دقیقاً چه کسی تعیین میکند چه چیزی باید تغییر کند. در نهایت، این شرکت در مورد نحوه رفتار مدلهایش حرف آخر را میزند و در پستی اظهار داشت که «امیدواریم این بینشهای اولیه را در اختیار ما قرار دهد زیرا فرآیندی قوی برای جمعآوری و ترکیب بازخورد ایجاد میکنیم تا اطمینان حاصل کنیم که مسئولانه به سمت مأموریت خود میسازیم». با ما همراه باشید در صورت انتشار اخبار جدید در رابطه با این موضوع بلافاصله آن را با شما به اشتراک خواهیم گذاشت. همچنین شما نیز میتوانید نظرات و پیشبینیهای خود را درباره قوانین پایه برای هوش مصنوعی و نتیجه اعمال آنها در آینده با ما در میان بگذارید.